How to use SkillOpt: train your agent skills, not your model
The new SkillOpt paper is easy to misread as prompt optimization. The useful lesson is more operational: treat skill files as trainable, validated artifacts.

The new SkillOpt paper is easy to file under "prompt optimization."
That is the least useful way to read it.
The practical lesson is stronger: a skill file can become a trainable operational artifact. Not a random prompt. Not a README someone patches after a bad run. A versioned document that changes only when the new version proves it is better.
That distinction matters if you build agents for real work. Most teams already have some version of skill files, system prompts, runbooks, playbooks, or AGENTS.md instructions. They are usually edited by instinct. The agent fails, someone adds a rule. The rule sounds right. The file gets longer. A month later nobody knows which instruction helped, which one did nothing, and which one quietly made another workflow worse.
SkillOpt, last revised on arXiv on May 25, 2026, gives that mess a training loop.
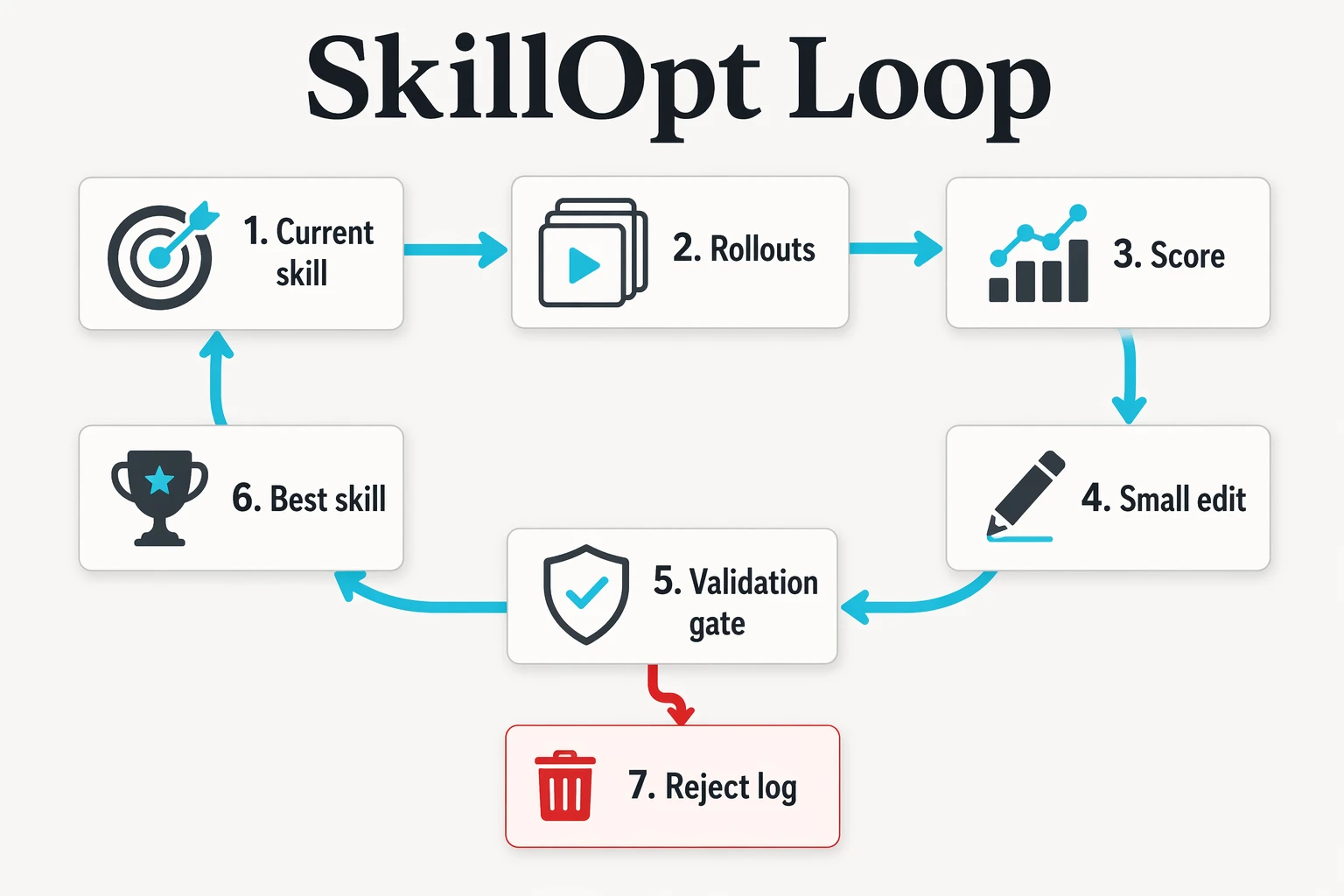
what SkillOpt actually changes
The paper's core move is simple: keep the target model frozen and train the skill document as external state.
The agent runs tasks with the current skill. Those trajectories are scored. A separate optimizer model looks at successes and failures, then proposes bounded edits to the skill file: add, delete, replace. A candidate edit is accepted only if it strictly improves a held-out validation score.
No tie accepted. No full rewrite because the new prompt feels cleaner. No "the agent reflected and improved itself" hand wave.
Small edit. Hard gate. Keep or reject.
The paper reports strong benchmark results: across six benchmarks, seven target models, and three execution harnesses, SkillOpt is best or tied in all 52 evaluated cells. On GPT-5.5, it reports average gains over no-skill accuracy of +23.5 points in direct chat, +24.8 inside the Codex loop, and +19.1 inside Claude Code. That same pattern shows up in long-horizon coding evals too: DeepSWE helps explain why Codex felt better than Claude on real execution work.
Those numbers are interesting. The operating model is more important.
If you run agents inside a company, the thing to copy is not the benchmark suite. It is the discipline around changing the instruction layer.
the part to copy
SkillOpt treats the skill file like a parameter you can inspect.
That is a useful middle ground. Fine-tuning changes weights you cannot easily read. A giant prompt can be read, but it usually changes without evidence. SkillOpt keeps the adaptation in plain text, but forces it through something closer to model-training discipline.
The output is also practical. The GitHub repo shows runs producing a best_skill.md alongside history, checkpoints, skill snapshots, and step artifacts. The project page makes the deployment point explicit: the target model consumes the final skill, not the optimizer memory.
That means the expensive or stronger model can be used during the improvement loop, while the deployed agent only needs the final skill artifact.
This is the pattern companies should steal.
how to use it this week
Start with one workflow. Not "make our agents better." Pick one skill that already matters.
Customer support triage. Pull request review. Meeting digest. Sales research. Document drafting. Deployment preparation. Anything where the agent has a repeatable job and a clear definition of failure.
Then build the loop.

- Freeze the current skill
Save the current skill file as the baseline. Do not compare against no skill. The question is whether the next version beats the thing you already rely on.
- Create a small eval set
Use real tasks. Ten good examples are better than fifty synthetic ones. Keep at least two splits: one for learning from failures, one held out for accepting or rejecting edits.
- Define what "better" means
This is where most teams will be weak. Do not only check whether the output has the right sections. Check the behavior you actually care about.
For a research skill: did it cite primary sources, reject weak sources, and preserve uncertainty?
For a support skill: did it load customer context before drafting, avoid unauthorized actions, and surface escalation cases?
For a writing skill: did it open with tension, use real proof, avoid generic AI phrasing, and keep unsupported claims out of the final?
- Run the baseline
Before editing, measure the current skill. Keep the outputs. Read them. The point is not only to produce a score. It is to understand what kind of mistake the skill keeps making.
- Allow only small edits
This is the most important habit. Do not rewrite the whole skill. Change one section. Add one invariant. Remove one confusing instruction. Replace one weak routing rule.
SkillOpt's edit budget is the text equivalent of a learning rate. If the step is too large, you lose causality. The file may look better, but you will not know what improved the behavior.
- Reject ties
If the candidate version does not beat the baseline on held-out tasks, it does not ship.
This feels harsh. It is supposed to. A lot of prompt edits sound smart because they are written in confident language. Skill files should not reward confidence. They should reward behavior.
- Keep a rejected-edit log
The rejected ideas are useful. They tell the next optimizer what not to try again.
In practice, this can be a simple file:
rejected-edits.jsonl
- tried adding a longer research checklist; outputs became slower and not more accurate
- tried forcing every article into a fixed structure; improved consistency, hurt readability
- tried stronger autonomy wording; increased risky tool useThat log is not bureaucracy. It is how the skill stops relearning the same bad lesson.
- Protect the slow knowledge
Some parts of a skill should not be touched by fast edits: safety rules, account identity checks, redaction rules, authority boundaries, irreversible-action gates.
SkillOpt uses slow/meta updates in its own loop. The company version is simpler: mark protected invariants and do not let normal optimization overwrite them.
That matters because agents do not only fail by being ineffective. They fail by becoming too confident in the wrong place.
validation is the product
The hard part of SkillOpt is not editing Markdown. Any model can do that.
The hard part is building a validation gate that measures what you actually value.
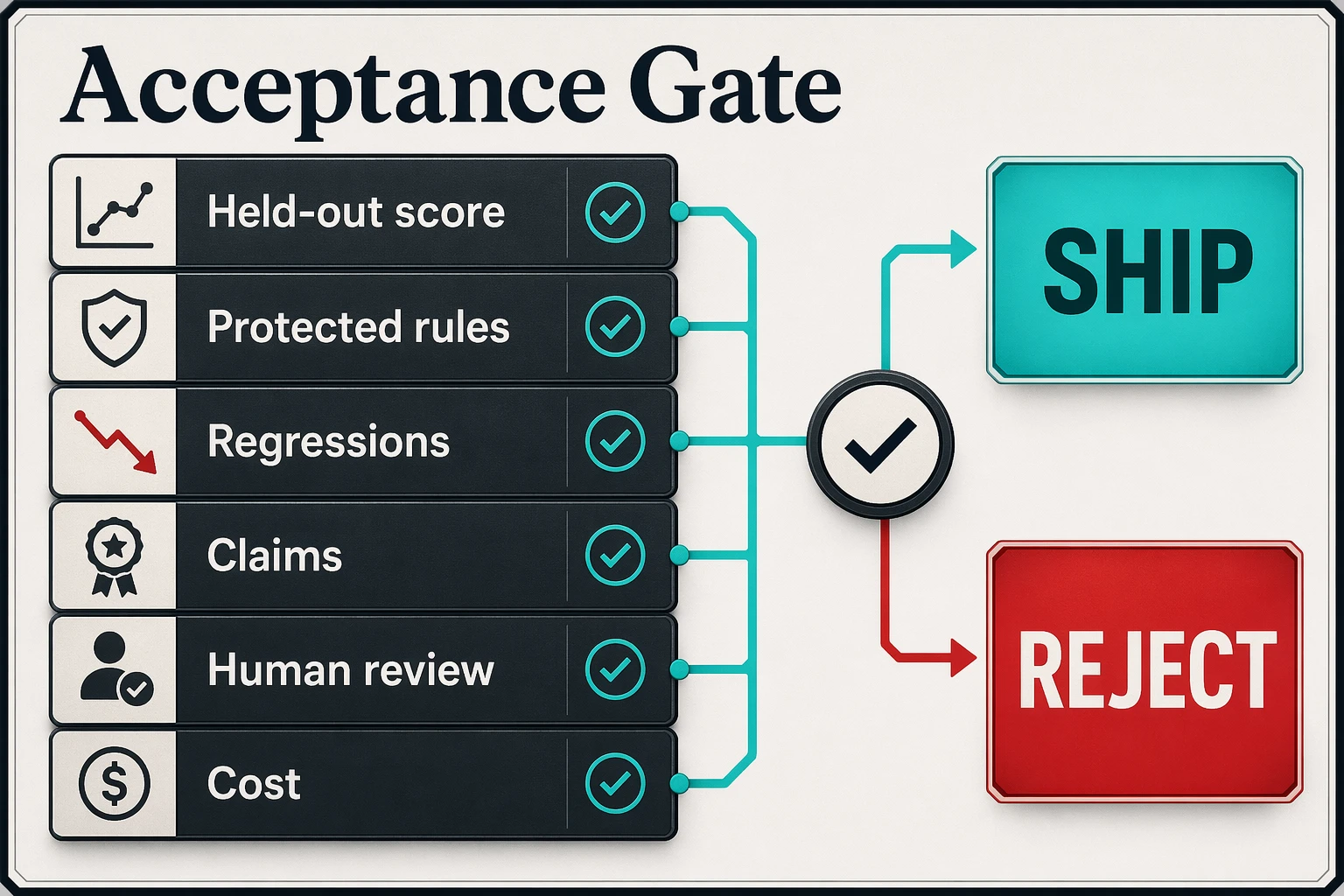
This is why the method is easier to apply to structured tasks than open-ended work. A spreadsheet task, navigation task, or QA task can often be scored. A strategy memo, brand voice, sales email, or article is harder. The model can satisfy a checklist while producing something nobody wants to read.
So if you apply SkillOpt-style loops to open-ended work, your eval cannot only check formatting. It needs adversarial review.
For content, that means checking whether the opening earns attention, whether claims are sourced, whether the piece contains proof an outsider could not invent, whether it sounds like a human with a point of view, and whether a smart reader would keep going after line three.
For company workflows, it means checking the invisible parts of good work: order of operations, escalation, redaction, source quality, approval boundaries, and taste.
This is the same argument we made in MCP is how agents learn your company's taste. Tool access is not enough. The method around the tool is where quality lives.
SkillOpt adds the missing training discipline to that method.
where it breaks
SkillOpt is not a license to let agents rewrite their own instructions in production.
That version is how you get prompt soup.
If the eval is weak, the skill will optimize toward the weakness. If the score rewards length, the skill gets longer. If the score rewards section coverage, the skill becomes a form-filling machine. If the score cannot see hallucinated confidence, the skill will learn to sound complete before it is correct.
The method works when the validation gate is stronger than the optimizer's ability to game it.
That is the uncomfortable part. Skill optimization does not remove judgment. It concentrates judgment into the eval design.
what this means for agent teams
The near-term playbook is not complicated.
Pick your most valuable agent workflow. Turn its instructions into a real skill file. Version it. Build a small eval set from real tasks. Add a held-out gate. Only accept narrow edits that beat the current version. Keep the rejects. Protect safety and authority rules. Deploy the best skill as a compact artifact.
That turns the instruction layer into company infrastructure.
It also changes how you think about memory. In Agents don't lack tools. They lack company memory., the argument was that agents need shaped, reusable company context. SkillOpt shows the same pattern from another direction: agents also need shaped, reusable company procedure.
The context tells the agent what the company knows.
The skill tells the agent how the company works.
Both should compound.
That is why the Markdown detail matters. A plain file can be read by a human, edited by an agent, reviewed in Git, tested against examples, rolled back, and carried across runtimes. The fact that the deployed artifact is just best_skill.md is not a limitation. It is the point.
We already see this direction inside our own work at The Vibe Company. The next layer after tools is not a bigger chat window. It is an operating system of memory, methods, reviews, and skills that agents can actually use. That is the broader reason we moved from Quivr to The Vibe Company.
SkillOpt gives one important piece of that operating system a name.
Do not train the model first.
Train the skill.
Then make every edit prove it deserves to stay.


